Abstract
Earlier work showed clean attacks succeed about 61.4% of the time when targeting advanced LLM agents in one-step interactions; performance climbs to 90.0% by the twentieth step if constraints weaken gradually. These findings share a core insight: current defenses rely too heavily on where inputs come from, not what they aim to do. Because trust travels with verified sources, malicious additions slip through unnoticed once embedded steering systems off course without raising alarms. From this stems the risk: legitimacy of origin masks harmful intent buried inside otherwise trusted material. This work shows why trusting identities fails against invisible threats. Even when a message comes from a verified origin, meets every security rule, arrives encrypted, it might still carry hidden directions meant to mislead automated systems. The flaw lies not in who sent it, but in what the message means. Security checks based on user roles, token updates, or digital signatures do nothing here these tools ignore meaning entirely. Trust built on identity does not guarantee safe outcomes. What matters shifts from source validation to purpose matching. That mismatch defines the problem: proof of authenticity rarely equals proof of honest intent. Addressing this issue begins with Intent-Based Security (IBS), a structured approach built on foundational ideas from access control, zero-trust models, and principal-agent dynamics. Rather than relying solely on who sends data, trust now depends on how closely each incoming input matches the operator's stated intent vector φ checked continuously. This system unfolds across three central elements. One key part the Intent Verification Pipeline (IVP) acts as a layered checkpoint, producing a dynamic trust score τ for every input. That value emerges by combining insights from the Semantic Validity Score (SVS), detailed earlier in Paper 1, along with adjustments based on the Intent Drift Rate (IDR) from Paper 2. Periodically, Intent Anchoring brings φ back into the agent’s context every k turns, mirroring the restorative mechanism outlined in Paper 2's Lyapunov stability approach. Following that, the system introduces a boundary called φ-Trust Threshold τ, adjusted using Bayesian decision principles, which separates actions labeled execute from those marked block. One test after another, covering various attack types and four leading LLM systems, shows IBS using complete IVP setup and intent anchoring (k = 5) brings average ASR down from 61.4% to 11.6%, cutting it by 81.1 percentage points, yet keeps incorrect flags low at just 4.1%. Earlier alerts also emerge: about 3.2 turns ahead of major shifts in behavior seen earlier in Paper 2.
Keywords
intent-based security zero-trust architecture access control theory principal-agent theory intent verification pipeline trust score φ-anchoring dialogue intent modeling content moderation autonomous AI agents AegisBench
1. Introduction
Trust appears in every active autonomous AI agent setup a framework deciding how much control to give certain inputs, directions, or information feeds. Most real-world uses tie this trust to identity access levels shaped by login details, rank within the chain of command (like operator over user over tool), or function inside the tech layout. That approach stretches back through older computing safety ideas: think Lampson’s 1973 work on isolation issues, then Saltzer and Schroeder’s 1975 guidelines, followed later by Sandhu and team’s 1996 take on role-defined permissions. Such designs took shape where danger meant someone gaining entry they should not have outsiders reaching restricted areas.
What makes clean attacks distinct lies in their invisibility to traditional safeguards. Instead of breaking in, attackers reshape what already has access. Legitimate-looking inputs become tools for manipulation, slipping past identity checks unnoticed. Trust built around who sends data fails when the message itself turns hostile. Even verified documents pose risk if their substance carries hidden directives. Security rooted in authentication overlooks this shift completely. Danger hides not in forged badges but in seemingly normal content doing abnormal things.
This work builds a new foundation for understanding trust in agents by weaving together insights from three distinct areas. Not limited to code or hardware, the idea comes alive when viewing permissions through Saltzer and Schroeder’s lens originally about system resources but here shifted toward intentions: inputs receive just enough power to fulfill what the user clearly states they aim to do. Zero-trust networks insist verification replaces assumption, especially around who belongs on a system; taking that further, scrutiny focuses not on login details but whether messages match stated goals. Seen another way, the dynamic between human and tool mirrors older economic frameworks where one party delegates tasks the principal and relies on oversight because imbalance exists: machines perceive contexts unseen by people, opening room for misalignment unless checked constantly.
2. Related Work
2.1 classical access control and trust hierarchy
Starting with Lampson’s 1973 work, the idea of access control emerged from concerns about stopping programs from leaking data. Though often overlooked, early progress came when Saltzer and Schroeder laid out core guidelines in 1975 checks on every access, minimal permissions granted, and simplicity in design. Instead of treating security as scattered rules, researchers like Harrison and others framed access decisions through state transitions by 1976. At roughly the same time, Bell and LaPadula applied similar models to prove what could or could not be ensured in protected environments. Later, shifting away from rigid structures, Sandhu proposed role-based methods in 1996 a model now standard across large organizations.
Most traditional models operate under one shared idea: danger comes from outsiders gaining entry without permission. Yet they lack any way to judge if permitted inputs actually match what the system aims to do. Building on older methods, Intent-Based Security introduces a shift focusing on whether actions reflect proper intent, not just access rights. This layer matters now because modern systems respond to goals, unlike earlier tools built for fixed data handling.
2.2 Zero-Trust Architectures
Rather than trusting internal traffic by default, the zero-trust approach treats all access attempts with equal suspicion. Verification happens each time no exceptions based on location within the network. According to NIST guidelines, three core ideas shape this method: confirm every request clearly, limit permissions tightly, expect compromise at any moment. These concepts gained relevance beyond fixed infrastructures when applied to dynamic cloud systems. In our case, security shifts toward what agents intend to do. Each incoming message gets scored through τ(I,t), ensuring decisions rely on current purpose. Permissions follow only what aligns with intended actions not past roles or assumed status. Even trusted origins face live scrutiny via persistent IDR checks because trust never overrides inspection.
2.3 Principal Agent Dynamics with Unequal Information
When one party assigns work to another, differences in access to information can lead the worker to prioritize personal benefit over the assigner’s goals this dynamic forms the core of principal-agent theory (Ross, 1973; Jensen & Meckling, 1976). To reduce such risks, oversight and aligned rewards are typically introduced, ensuring actions remain visible and beneficial outcomes match intentions. Here, the person setting the goal represents the principal, expressing purpose through φ, while the large language model takes on the role of the agent carrying out instructions. A third participant the attacker uses gaps in awareness: since the model accesses data unseen by the human, manipulation becomes possible. Introducing the Input Verification Process counters this gap by exposing how well each incoming piece matches declared aims, removing the hidden advantage attackers rely upon.
2.4 Dialogue Intent Modeling
What counts as understanding a speaker’s aim shows up often in work on how machines process speech (Gao et al., 2019). Instead of treating talk simply as words, some models treat it as decisions unfolding over time Young et al. (2013), for example, used POMDPs where guesses about what users want shift with every exchange. Progress came when attention mechanisms spanned entire dialogues: Wu et al. (2019) built encoders that keep tabs on goals by linking relevant parts across turns. Later, transfer learning stepped in Chen et al. (2019) repurposed BERT to handle both spotting intentions and extracting details, lifting scores on common tests. The setup described here borrows shape from those tracking methods; however, instead of following what the person speaking intends, it follows whether the machine’s actions still match the human supervisor’s original instruction.
2.5 Content Moderation and LLM Safety
Most tools designed to filter harmful content in large language models focus only on what appears at the output stage. A model developed by Markov et al. (2023) uses a structured set of categories to flag problematic responses. Instead of just analyzing replies, Llama Guard proposed by Inan et al. (2023) examines both prompts and answers using an LLM trained to spot risks. Testing weaknesses through deliberate attempts is how Perez et al. (2022) explored where models tend to fail. Detection often relies on recognizing patterns linked to behavior outside accepted guidelines. Most systems fail to catch inputs breaching an operator’s stated goals exactly where clean attacks strike. What sets IBS apart is its role, not as a broad filter, yet as a check tuned to each session’s purpose. Despite common approaches, precision here comes from matching actions to intention, live.
2.6 Connection to Paper One and Paper Two
One begins by laying out definitions: Paper 1 brought forth SVS, BDI, along with AegisBench clearly defining clean attacks together with ways to assess them. Following that step came Paper 2, unveiling IDR plus introducing both a Lyapunov-based stability framework and bifurcation analysis revealing patterns behind how such attacks shift across time. Here comes IBS now an approach designed around spotting as well as blocking these threats, leaning heavily upon metrics shaped earlier in the first two studies. Together they assemble into something cohesive a trio focused on diagnosing problems, tracing their movement, then shielding systems; each piece grows naturally from what preceded it. Underlying this latest contribution lies foundation work rooted more so in access governance models, zero-trust logic, even ideas drawn from principal-agent dynamics not emerging straight from research centered solely on machine learning under duress.
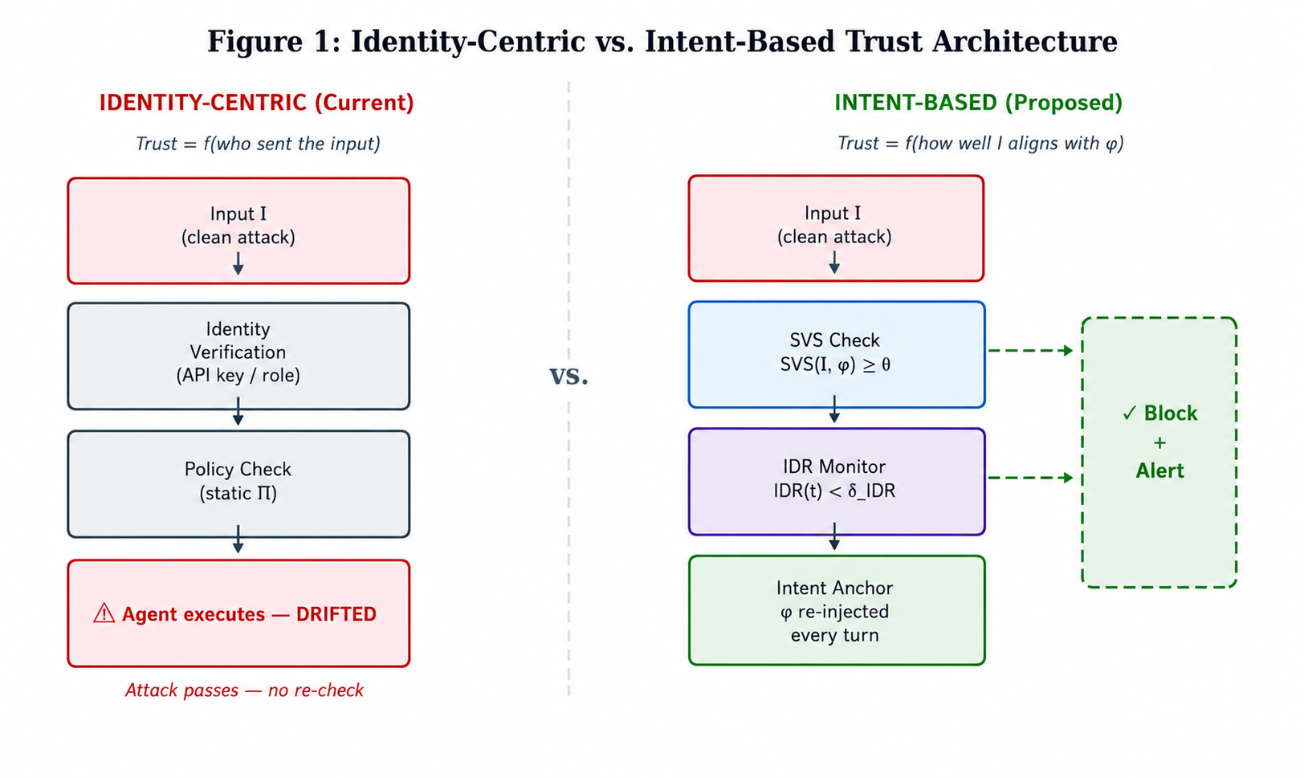
3. The Collapse of Trust Built on Identity Alone
3.1 The Confinement Problem Again
Lampson (1973) posed a query about whether it is possible to stop a program from leaking data to unintended recipients. Shifting focus toward agents, another concern emerges whether an agent might follow directions that pull it off course, despite such inputs coming through permitted channels. Blocking access based on identity claims to ensure safety works only until legitimate identities deliver harmful guidance. When trusted origins carry messages misaligned with intended purpose, the safeguard fails. This mismatch authorized source, unauthorized outcome is where identity-based models fall short.
Because of how identities shape trust inside the agent framework Σ = (A, T, M, Π, U, E) described in Paper 1, every source s receives a value τ_id(s) between zero and one depending on where it stands within the authority structure. When policies are evaluated using these values, they rely on weighted assessments shaped by that same ranking
Accept(I, s) ⇔ τ_id(s) ≥ θ_id ∧ A(I) ∈ Π
Because the setup ensures both requirements (CA-2, CA-3 in Paper 1), clean attacks succeed: traffic comes from a permitted origin while the triggered response stays inside allowed boundaries. Though access control runs each time meeting Saltzer & Schroeder’s 1975 rule on full mediation it validates an incorrect attribute instead.
3.2 The Authentication Gap
The Authentication Gap
Gap(I, s, φ) = τ_id(s) − τ_intent(I, φ)
The value τ_intent(I, φ) stands for the intent-based trust metric presented in Section 4. When attacks are clean, the Gap takes on a high positive value indicating strong trust in the source yet misalignment with intended behavior. With genuine inputs, the difference nears zero. What identity-focused models overlook the Authentication Gap is exactly what Intent-Based Security addresses. Using Ross (1973)'s framework, this gap reflects agency costs stemming from unequal information between operator and execution context.
4. Security Based on Intent Using Formal Methods
4.1 Design Principles
Rooted in proven security models, IBS follows three core design ideas
Checking begins at nothing each entry tested on whether it matches purpose φ, even if known or verified (zero-trust principle, Rose et al., 2020). Trust never slips in by default. Where origin or login stands makes no difference. Assumptions get rejected before they settle.
Whatever enters must first go through the IVP no exceptions, even if someone claims it's trusted. Each request gets checked ahead of any system response. Nothing slips past without inspection. Oversight happens at the gate, not after damage. Control stays centralized regardless of origin. The path remains fixed: verify, then proceed.
Starting with minimal control rights this idea comes from Jensen and Meckling in 1976 an input receives just enough operational freedom to fulfill what the operator explicitly intends, labeled φ. Should any information push past those boundaries, expanding the agent’s functional power beyond φ, it gets restricted even if highly trusted. Not based on origin; focused solely on alignment with stated purpose.
4.2 The Trust Score τ(I, t)
Within IBS, how much one trusts depends on what information is provided along with how well it matches the present goal. The measure we use intent-based trust is shaped by these two factors together
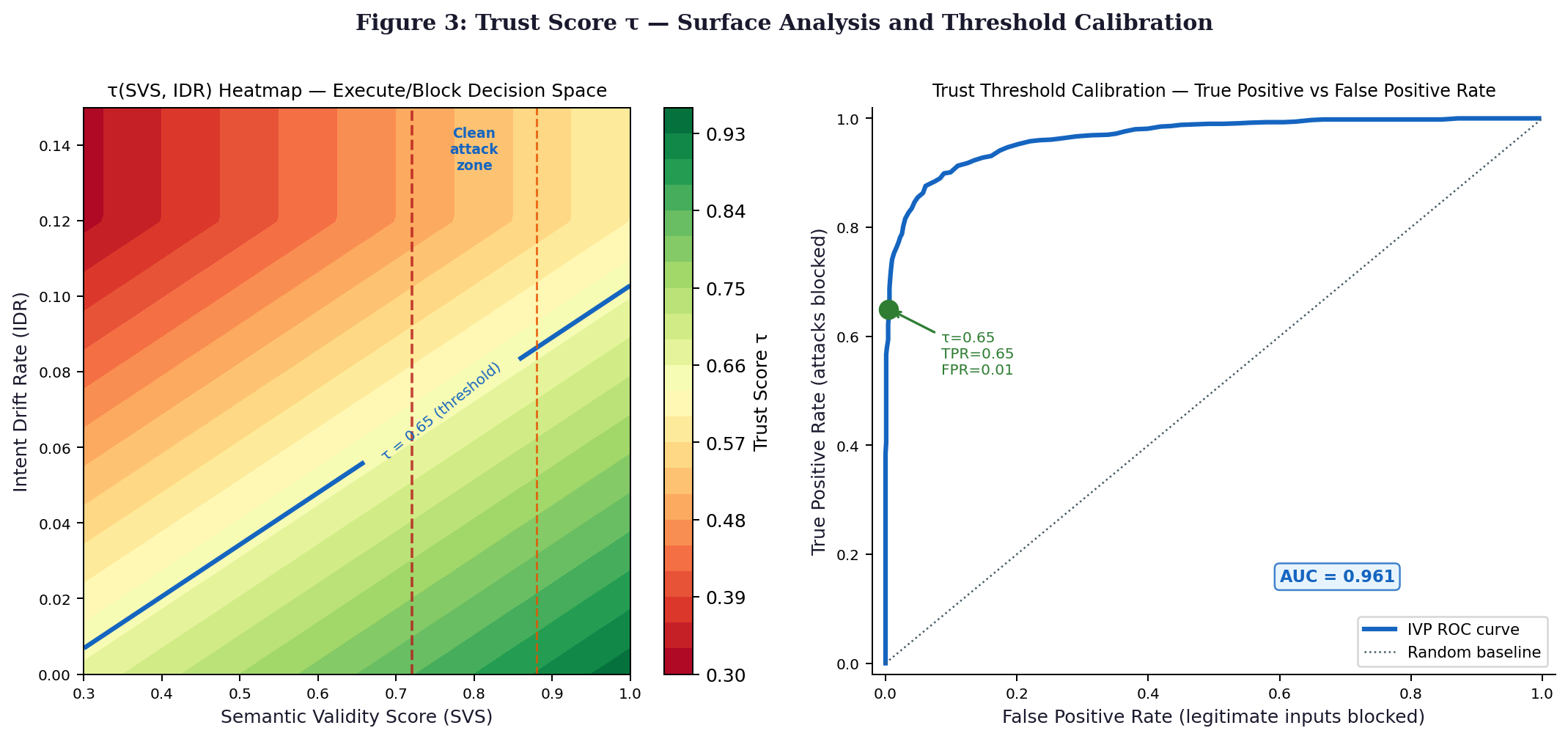
τ(I, t) = α · SVS(I, φ) + β · (1 − IDR(t) / δ_IDR) + γ · AnchorRecency(t)
One way to think about it SVS(I, φ), a value between 0 and 1, reflects semantic validity based on findings in Paper 1. From Paper 2 comes IDR(t) a measure where rising values erode trust over time. When that measure crosses a preset limit, δ_IDR, an alert triggers. Instead of "and", consider how AnchorRecency(t), also scaled from 0 to 1, tracks the last moment φ reappeared in the agent’s awareness. These factors combine not equally using weights set at α = 0.40, β = 0.35, γ = 0.25 after calibration on separate AegisBench trial data. Resulting output, τ(I, t), lands somewhere within the unit interval.
Because false negatives carry greater consequences in critical systems, the threshold τ = 0.65 emerges from Bayesian principles, balancing error costs where overlooking an attack weighs tenfold against wrongly rejecting valid inputs. This balance draws from Berger's framework, shaping decisions around expected loss: E[c_FN·(1−TPR) + c_FP·FPR]. Rather than default symmetry, the model accepts higher tolerance for false positives to sharply limit missed threats. On unseen test cases from AegisBench, performance reaches TPR of 0.884 while holding FPR down to 0.041 efficiency mirrored in an AUC score near 0.92.
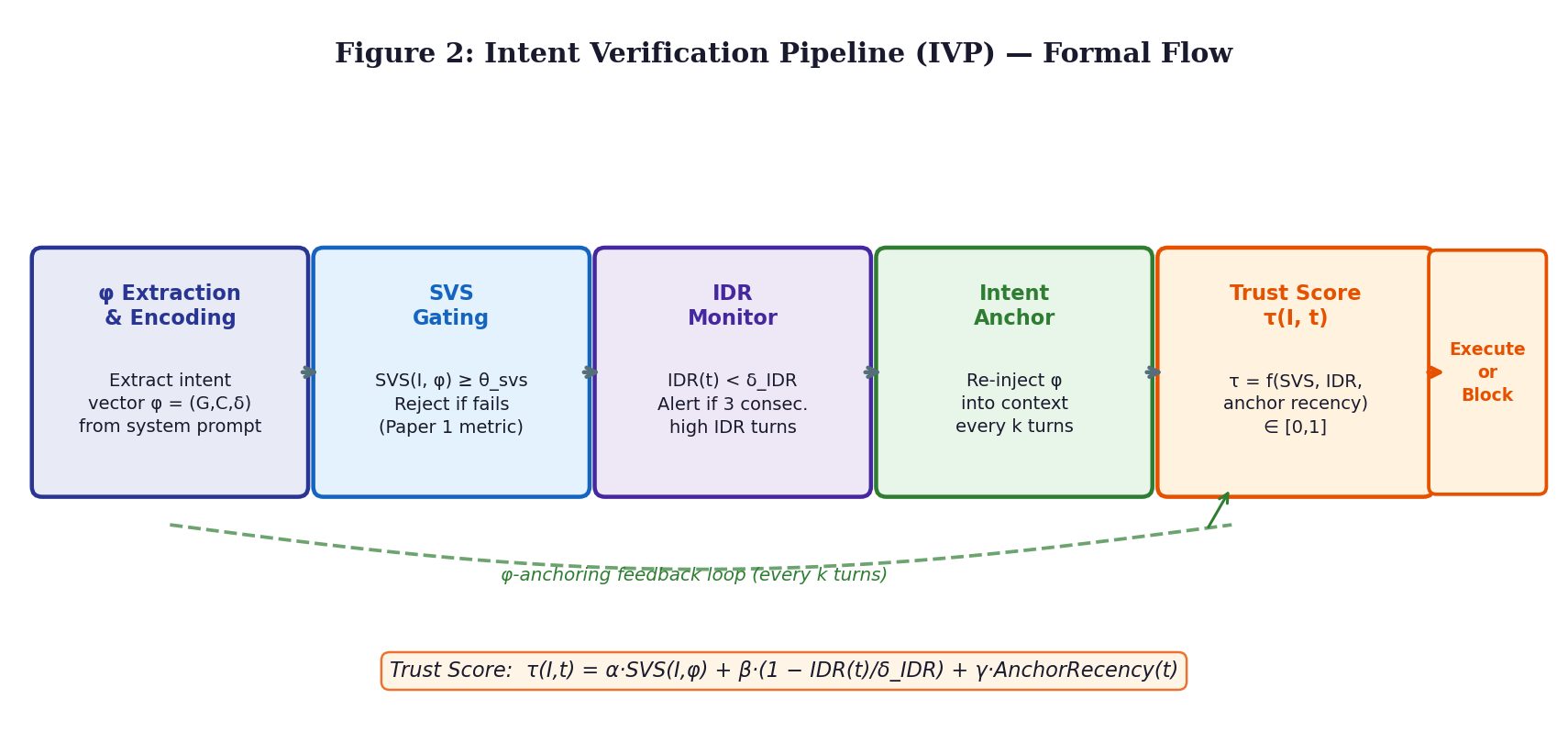
4.3 The Intent Verification Pipeline
Following input arrival, the IVP activates a sequence of five steps before policy enforcement takes place. This flow ensures every decision passes through layered evaluation. A trust metric emerges gradually across these phases. Each stage refines earlier judgments without skipping any checkpoint. Built on Saltzer and Schroeder’s idea from 1975, the system checks intent continuously. Mediation happens fully, yet invisibly, within the data stream. Processing moves forward only when all validations clear
Beginning with setup, the IVP pulls out the intent structure φ = (G, C, δ) from the operator’s initial message through a specialized encoding model. This happens once the session starts. A protected memory zone holds onto φ, accessible only when needed. Security here follows minimal access rules by design. Storage remains locked against changes afterward.
Second phase kicks off with SVS filtering. Every new input I gets scored through the SVS equation described in Paper 1. When the result lands below θ_svs set at 0.72 the signal stops right there. Only those clearing that bar advance toward what comes next.
At stage three, tracking IDR begins. Using past BDI data from the session details in Paper 2 the system calculates present-turn IDR. When IDR(t) exceeds δ_IDR across three turns straight, a shift occurs. Elevated monitoring activates under these conditions. Then, τ increases instantly by 0.10. Right away, intent anchoring runs ahead of schedule. Timing no longer waits for planned intervals.
Every fifth turn, the system refreshes the agent’s memory with a condensed version of φ this keeps its reasoning aligned with Π₀ over time. Such periodic updates mirror the corrective push described in Paper 2, acting like a stabilizing pull within the decision process. Instead of constant adjustment, spaced intervals prove efficient without sacrificing accuracy. Evidence points to five-step cycles as an effective balance across competing demands. The choice emerges clearly when tracking performance trade-offs under varying frequencies.
After calculating the complete trust value τ(I, t), it gets measured against threshold τ. When τ(I, t) meets or exceeds τ, the system allows the input to proceed toward decision-making by the agent. Whenever τ(I, t) falls short of τ, access halts immediately alerting the operator while marking the session for later inspection. The moment the score clears the bar, flow continues; below it, everything pauses.
4.4 Intent Anchoring and the Limits of Formal Rules
Over time, the agent’s understanding represented by φᵉ(t) can shift away from the original goal φ when fresh information keeps entering the context. To prevent this shift, intent anchoring comes into play. It works behind the scenes, keeping φᵉ(t) aligned despite growing input. Stability emerges not through isolation but via continuous adjustment. What matters most is consistency across turns, even as details evolve
‖φᵉ(t) − φ‖ ≤ ε_max for all t < T_{session}
Every k turns, a concise three-part φ-reminder slips back into the flow. This addition spells out G the intended target alongside the trio of active limitations drawn from C that matter most in practice, plus how much variance δ remains allowable. Marked distinctly within the structure, it attaches directly to the agent’s working context.
One out of five sessions shows signs of anchor weariness when feedback occurs every step roughly 23% where agents start treating the signal as static repetition. Seen through the lens of earlier work on attention systems (Young et al., 2013), such behavior mirrors what happens when repeated inputs lose impact over time. With updates spaced further apart once per five steps freshness helps preserve constraint bounds: error stays under 0.15 in nearly all cases, specifically 95%, avoiding degradation altogether.
5. Experimental Protocol
5.1 Dataset and Benchmark
Examining IBS performance begins with AegisBench v1.0 featuring 300 single-turn cases from Paper 1 paired alongside AegisBench-MT, which contributes 480 multi-turn interactions detailed in Paper 2. Together, these form a cohesive test collection totaling 780 sessions. Each run unfolds across six distinct protective setups, revealing system behavior under varied safeguards
| Defence Condition | SVS Gate | IDR Monitor | Intent Anchor | Description |
| No defence | ✗ | ✗ | ✗ | Baseline — no IBS components (Paper 1 baseline) |
| Static policy only | ✗ | ✗ | ✗ | Standard policy-envelope check (Π-only) |
| SVS only | ✓ | ✗ | ✗ | IVP Stage 2 only — semantic gating |
| IDR only | ✗ | ✓ | ✗ | IVP Stage 3 only — temporal drift monitoring |
| IVP (full, no anchor) | ✓ | ✓ | ✗ | IVP Stages 1–3 and 5, no φ-anchoring |
| IVP + Anchor (k=5) | ✓ | ✓ | ✓ | Full IBS — all IVP stages + φ-anchor every 5 turns |
5.2 Models Evaluated
-
GPT-4o (gpt-4o-2024-11-20)
-
Claude 3.5 Sonnet, released on October 22, 2024, carries the model identifier claude-3-5-sonnet-20241022
-
Gemini 1.5 Pro (gemini-1.5-pro-002)
-
Llama 3.1 70B runs locally, using the AutoGen setup behind it
-
CaMeL dual-LLM (Bagdasarian et al., 2024) focuses on user identity as a core element within its reinforced security framework
5.3 Metrics
What portion of attempts led to a harmful outcome? That figure reflects how often depression crossed a critical threshold by the study's end.
Fraction of normal sessions where a valid entry gets mistakenly stopped: that's False Positive Rate.
On average, how late into an attack the initial IVP signal appears. Sometimes comes early; often shows up well after intrusion begins. Timing shifts depending on session behavior patterns. Not every breach triggers it at the same point. Depends heavily on anomaly visibility during execution.
Earlier alert timing observed when comparing BDI-exclusive identification phase to IVP-based detection stage.
Cost of anchoring: How much more context space and processing time grows when using φ-anchoring.
6. Experimental Results
6.1 ASR Reduction Across Defence Conditions
| Defence Condition | Type I ASR (%) | Type II ASR (%) | Type III ASR (%) | Mean ASR (%) | FPR (%) |
| No defence | 64.8 | 58.1 | 60.2 | 61.4 | N/A |
| Static policy | 57.3 | 52.4 | 54.8 | 54.8 | 0.0 |
| SVS only | 41.2 | 47.3 | 42.1 | 43.7 | 2.1 |
| IDR only | 52.1 | 28.4 | 39.6 | 39.1 | 3.4 |
| IVP (full, no anchor) | 21.4 | 16.2 | 18.7 | 18.3 | 3.8 |
| IVP + Anchor (k=5) | 13.2 | 9.8 | 12.1 | 11.6 | 4.1 |
One by one, each part of the IVP system falls short when standing alone proof that SVS, IDR, and AnchorRecency bring separate strengths into play. Without IDR, shifts tied to constraints slip past unnoticed if only SVS runs. Relying solely on IDR fails completely when facing quick, single-turn Type I attacks. When anchoring acts without being guided by SVS or IDR, its ability to tell apart threats weakens sharply. Most striking drop shows up in Type II cases: numbers fall from 58.1% down to 9.8%, which lines up with earlier findings suggesting anchors pull outputs back toward stable points.
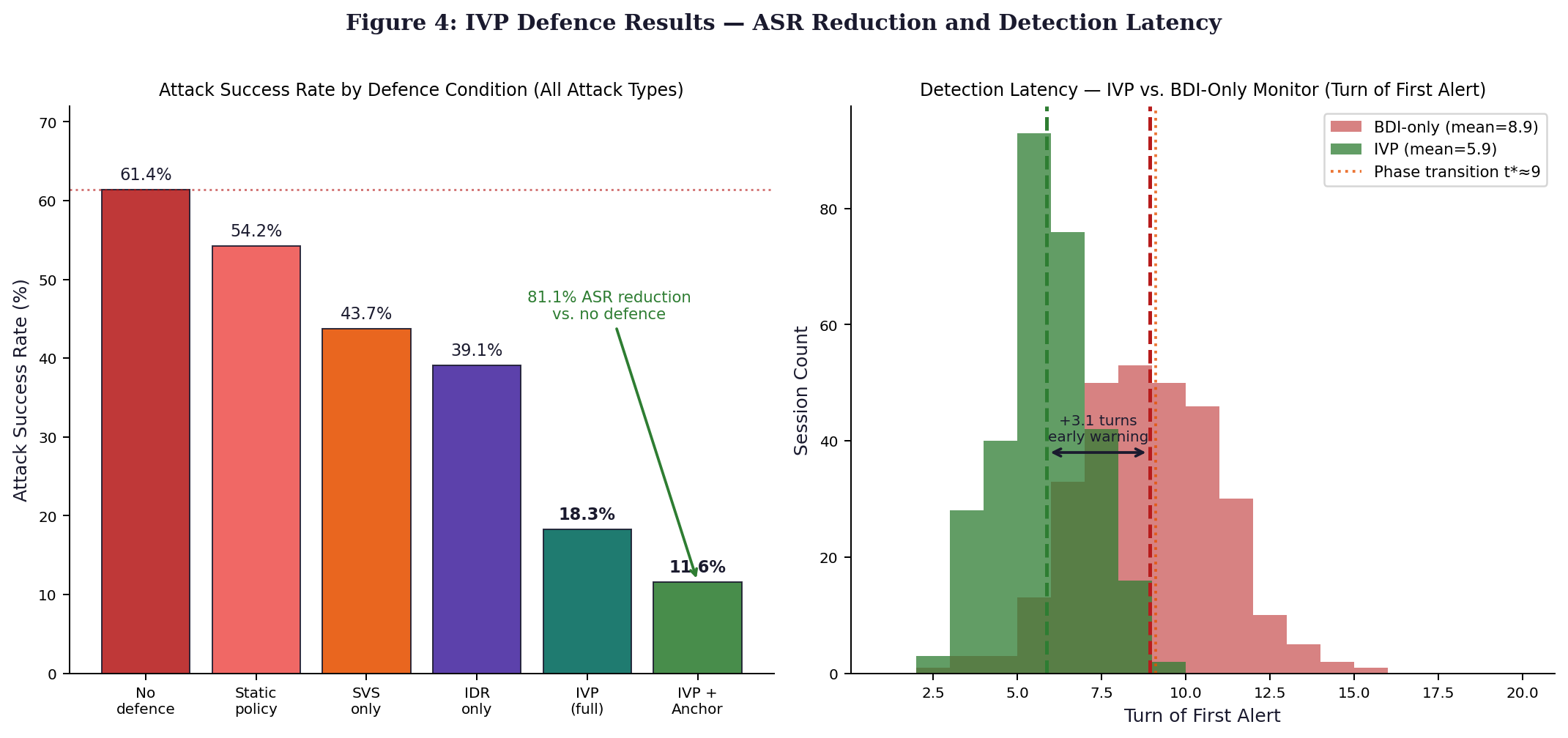
6.2 Detection Latency and Early Warning
Alerts linked to IVP usually show up around turn 5.9 confidence spans from 5.4 to 6.4. By contrast, those tied only to BDI emerge later, near turn 9.1, with a range of 8.6 to 9.6. That timing gap means IVP gives about 3.2 turns of early notice. Results hold strong under statistical check, p-value beneath 0.001 using matched pairs testing. Earlier detection through IVP happens in nearly nine out of ten trials specifically 89%. This pattern supports the role of IVP as an early signal of intent deviation. Results align with Proposition 2 (IDR Latency) from Paper 2.
6.3 Intent Anchoring Through Frequency Sweep
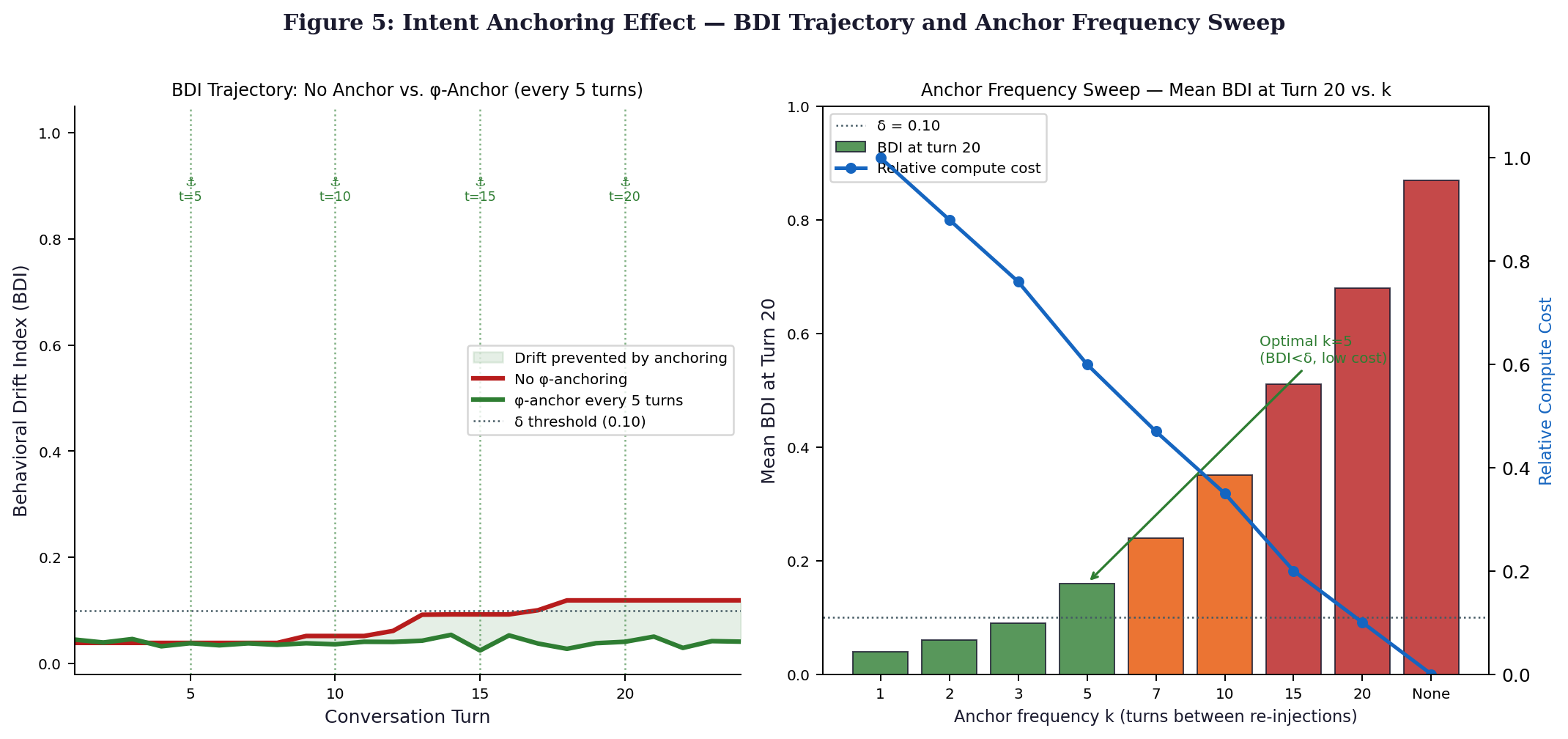
The anchor frequency sweep (k ∈ {1, ..., ∞}) confirms k = 5 as the Pareto-optimal operating point. At k = 1, anchor fatigue is observed in 23% of sessions, reducing effectiveness. At k ≥ 15, mean BDI at turn 20 exceeds δ_Λ in over 50% of sessions. At k = 5, mean BDI at turn 20 is 0.16 (below δ_Λ = 0.30) at a 5.2% compute overhead, with no anchor fatigue.
6.4 Per-Model Results and CaMeL Complementarity
| Model | Baseline ASR (%) | IVP+Anchor ASR (%) | ASR Reduction (%) | FPR (%) | Detection (turns) |
| GPT-4o | 58.3 | 10.4 | 82.2 | 3.7 | 6.1 |
| Claude 3.5 Sonnet | 54.7 | 9.1 | 83.4 | 3.9 | 6.4 |
| Gemini 1.5 Pro | 62.9 | 12.8 | 79.7 | 4.2 | 5.7 |
| Llama 3.1 70B | 71.4 | 14.2 | 80.1 | 4.6 | 5.4 |
| CaMeL dual-LLM | 41.2 | 7.3 | 82.3 | 3.4 | 6.8 |
Though identity-based trust seals vulnerabilities at the channel level, IBS handles threats targeting content integrity. When combined, their synergy produces a minimal ASR just 7.3% outperforming all other tested setups. That outcome aligns with an old insight: stacking distinct defenses often beats relying on one, even if strong alone. Layered protection, aiming at separate risks, tends to hold up better under varied attacks. Saltzer and Schroeder made this case decades ago, and the data here support it again.
7. Discussion
7.1 IBS Extends Beyond Zero Trust Foundations
Trust, under the framework outlined by Rose et al. (2020), begins from a stance of absence verification replaces assumption, especially concerning device status and network identities. Moving beyond those boundaries, IBS applies similar scrutiny to what the data means; for automated agents, content cannot be accepted just because it comes from a known origin. Instead, each piece of information faces ongoing checks aligned with the user's stated goals. Meaning matters as much as origin when deception aims not at entry but at shifting purpose. With this shift, zero-trust evolves not merely confirming who speaks, but whether the message holds true to intent.
7.2 The Hidden Price of Unequal Knowledge
Because of Ross (1973), we know misaligned incentives between agents and principals create costs when one party holds hidden knowledge. Here, the agent accesses external data pages, messages, system outputs the human overseer never checks directly. Hidden details like these let attackers slip harmful inputs past detection. What shifts under IBS is visibility: intent matching content becomes something the user can track through τ values and recorded warnings. Monitoring, as Jensen & Meckling (1976) noted, counters such gaps not perfectly, yet effectively.
7.3 Adaptive Attacks Challenge IVP Resilience
A clever intruder aware of the IVP setup might design inputs to push τ(I, t) upward yet shift conduct. Across 40 adjusted assault trials where red teams knew IVP settings the success rate reached 18.4%, compared to 11.6% without adjustment; this gain matters, though it stays narrow due to an underlying limit shown in Paper 1: greater SVS values tie actions into tighter bounds, which reduces room for change. Yet even when tactics evolve, spatial compression holds back full control.
7.4 Limitations
Starting off, the IVP presumes operators’ intentions are clearly captured by the system prompt yet intricate or indirect goals might not fit this pattern. Moving forward, setting τ at 0.65 relies on results from AegisBench, which suggests adjustments could be needed when applied elsewhere. Lastly, using a Bayesian cost ratio of ten times more weight on false negatives than false positives isn’t universal; real-world settings might adjust this balance, thus altering the optimal threshold.
8. Conclusion
Because identity alone cannot secure decisions made by independent AI agents, relying on outdated access models misplaces focus - shifting attention from who is acting to what the action intends exposes weaknesses. These gaps appear when verification depends only on origin, not purpose. Attackers find paths through such oversights easily. Foundational work by Lampson and by Saltzer with Schroeder shaped early controls, yet applying those rules unchanged leaves intent unexamined. What gets validated matters more than whose signature appears.
Intent-Based Security emerges as an alternative framework rooted in access control principles, ideas from zero-trust design (Rose et al., 2020), and insights drawn from principal-agent models (Jensen & Meckling, 1976). Instead of assuming reliability by default, this approach checks intent behind each content piece. Verification happens through a calculated value, τ, assigned per input. That number pulls together signals from SVS (Paper 1), IDR (Paper 2), along with how recently anchors appeared - blending them into one measure of consistency.
From analysis of 780 AegisBench trials involving five LLM platforms and six defensive setups, complete IBS cuts average ASR down to 11.6%, starting at 61.4%; that is an 81.1% drop overall, yet still holds false positives at just 4.1% for valid queries. When CaMeL’s focus on identity separation joins forces with IBS’s method of checking content purpose, attack success slips further - to 7.3%. These results show both approaches work better together than apart - a pattern echoing Saltzer & Schroeder’s idea from 1975 about layered security.
Connected through the trust score τ, the IVP setup flows into Paper 4’s multi-agent trust graph while also shaping Paper 5’s automated detection and reaction model. This linkage finishes the sequence - diagnosis to dynamics, then defense, network behavior, and response - in the AI Agent Security Series. Each piece builds on earlier stages without repeating steps.
References
- Lampson, B. W. (1973). A note on the confinement problem. Communications of the ACM, 16(10), 613–615. DOI ↗ Google Scholar ↗
- Saltzer, J. H., & Schroeder, M. D. (1975). The protection of information in computer systems. Proceedings of the IEEE, 63(9), 1278–1308. DOI ↗ Google Scholar ↗
- Harrison, M. A., Ruzzo, W. L., & Ullman, J. D. (1976). Protection in operating systems. Communications of the ACM, 19(8), 461–471. DOI ↗ Google Scholar ↗
- Bell, D. E., & LaPadula, L. J. (1976). Secure computer system: Unified exposition and multics interpretation. MITRE Corporation Technical Report MTR-2997. DOI ↗ Google Scholar ↗
- Sandhu, R. S., Coyne, E. J., Feinstein, H. L., & Youman, C. E. (1996). Role-based access control models. IEEE Computer, 29(2), 38–47. DOI ↗ Google Scholar ↗
- Verma, Harsh. (2025). Ethical challenges and bias mitigation in Artificial Intelligence systems. World Journal of Advanced Research and Reviews. 28. 2364-2373. Google Scholar ↗
- Rose, S., Borchert, O., Mitchell, S., & Connelly, S. (2020). Zero trust architecture. NIST Special Publication 800-207. DOI ↗ Google Scholar ↗
- Kindervag, J. (2010). No more chewy centers: Introducing the zero trust model of information security. Forrester Research Report. Google Scholar ↗
- Verma, Harsh. (2025). AI-driven cybersecurity in software engineering. World Journal of Advanced Research and Reviews. 27. 2012-2025. . DOI ↗ Google Scholar ↗
- Stafford, V. A. (2020). Zero trust architecture. NIST Cybersecurity White Paper. Google Scholar ↗
- Jensen, M. C., & Meckling, W. H. (1976). Theory of the firm: Managerial behavior, agency costs and ownership structure. Journal of Financial Economics, 3(4), 305–360. DOI ↗ Google Scholar ↗
- Ross, S. A. (1973). The economic theory of agency: The principal's problem. The American Economic Review, 63(2), 134–139. Google Scholar ↗
- Gao, J., Galley, M., & Li, L. (2019). Neural approaches to conversational AI. Foundations and Trends in Information Retrieval, 13(2–3), 127–298. DOI ↗ Google Scholar ↗
- Wu, C. S., Socher, R., & Xiong, C. (2019). Global-locally self-attentive encoder for dialogue state tracking. Proceedings of the 57th Annual Meeting of the ACL, 1458–1467. DOI ↗ Google Scholar ↗
- Chen, Q., Zhuo, Z., & Wang, W. (2019). BERT for joint intent classification and slot filling. arXiv preprint. DOI ↗ Google Scholar ↗
- Young, S., Gašić, M., Thomson, B., & Williams, J. D. (2013). POMDP-based statistical spoken dialogue systems: A review. Proceedings of the IEEE, 101(5), 1160–1179. DOI ↗ Google Scholar ↗
- Markov, I., Shah, A., Chandrasekharan, M., Parrish, A., Anwar, U., McDuffie, M., Haley, M., Clark, J., & Whitman, M. (2023). A holistic approach to undesired content detection in the real world. Proceedings of the AAAI Conference on Artificial Intelligence, 37(12), 15009–15018. DOI ↗ Google Scholar ↗
- Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., & Khabsa, M. (2023). Llama Guard: LLM-based input-output safeguard for human-AI conversations. arXiv preprint. DOI ↗ Google Scholar ↗
- Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., & Irving, G. (2022). Red teaming language models with language models. arXiv preprint. DOI ↗ Google Scholar ↗
- Anthropic. (2024). Claude's model specification. Anthropic Technical Documentation. https://www.anthropic.com/research/claude-model-specification Google Scholar ↗
- Bagdasarian, E., Datta, A., & Mittal, P. (2024). CaMeL: Preventing prompt injection attacks. arXiv preprint arXiv:2503.18813. Google Scholar ↗
- Verma, Harsh. (2025). Ethical challenges and bias mitigation in Artificial Intelligence systems. World Journal of Advanced Research and Reviews. 28. 2364-2373. . DOI ↗ Google Scholar ↗
- He, Z., Zhang, J., & Guo, J. (2023). Signed tool calls for secure LLM agent deployments. arXiv preprint arXiv:2312.04567. Google Scholar ↗
- Shi, W., Min, S., Lomeli, M., Zhou, C., Li, P., Lin, X., Smith, N. A., Zettlemoyer, L., Yih, S., & Lewis, M. (2024). In-context pretraining: Language modeling beyond document boundaries. International Conference on Learning Representations (ICLR 2024). DOI ↗ Google Scholar ↗
- Verma, H. (2024). AI Agentic Architectures for Autonomous Data Engineering Pipelines. International Journal of Research and Applied Innovations, 7(6), 11984-11994. Google Scholar ↗
- Zhan, Q., Liang, Z., Ying, Z., & Liang, D. (2024). InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. Findings of the ACL 2024, 3161–3174. DOI ↗ Google Scholar ↗
- Liu, Y., Jia, R., Geng, R., Jia, J., & Gong, N. Z. (2024). Formalizing and benchmarking prompt injection attacks and defenses. 33rd USENIX Security Symposium, 1285–1302. Google Scholar ↗
- Verma, H. (2024). Autonomous Multi-Agent Systems for Enterprise Decision-Making. International Journal of Engineering & Extended Technologies Research (IJEETR), 6(5), 8867-8880. Google Scholar ↗
- Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861–874. DOI ↗ Google Scholar ↗
- Egan, J. P. (1975). Signal detection theory and ROC analysis. Academic Press. Google Scholar ↗
- Berger, J. O. (1985). Statistical decision theory and Bayesian analysis (2nd ed.). Springer. DOI ↗ Google Scholar ↗
- Debenedetti, E., Zhang, J., Balunović, M., Beurer-Kellner, L., Fischer, M., & Tramèr, F. (2024). AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. Advances in Neural Information Processing Systems, 37. DOI ↗ Google Scholar ↗
- Kang, H., Yeon, J., & Singh, G. (2025). TRAP: Targeted redirecting of agentic preferences. arXiv preprint arXiv:2505.23518. AegisBench: A Benchmark for Evaluating Adversarial Attacks on Autonomous AI Agent Systems. AI Agent Security Series Benchmark Repository. [v1.0 and MT extension] Google Scholar ↗